20 Sep
smartphone

In einem neuen Forschungspapier, in dem seine KI-Trainingsfunktionen für das iPhone und andere Produkte detailliert beschrieben werden, scheint sich der Technologieriese Apple dafür entschieden zu haben, sich auf die Chips von Google statt auf die des Marktführers NVIDIA zu verlassen. In dem Papier teilt Apple mit, dass sein Apple Foundation Model (AFM) mit 2,73 Milliarden Parametern v4- und v5p-Tensor-Processing-Unit-Cloud-Cluster (TPU) verwendet, die von Google von Alphabet Inc. bereitgestellt werden.
Apple gibt bekannt, dass es ein 6,3 Billionen Token umfassendes KI-Modell „von Grund auf“ auf „8192 TPUv4-Chips“ trainiert. Für geräteinterne KI-Modelle, die für Funktionen wie Tippen und Bildauswahl verwendet werden, verwendet Apple ein 6,4 Milliarden Parameter umfassendes Modell, das auf 2048 TPU v5p-Chips trainiert wurde.
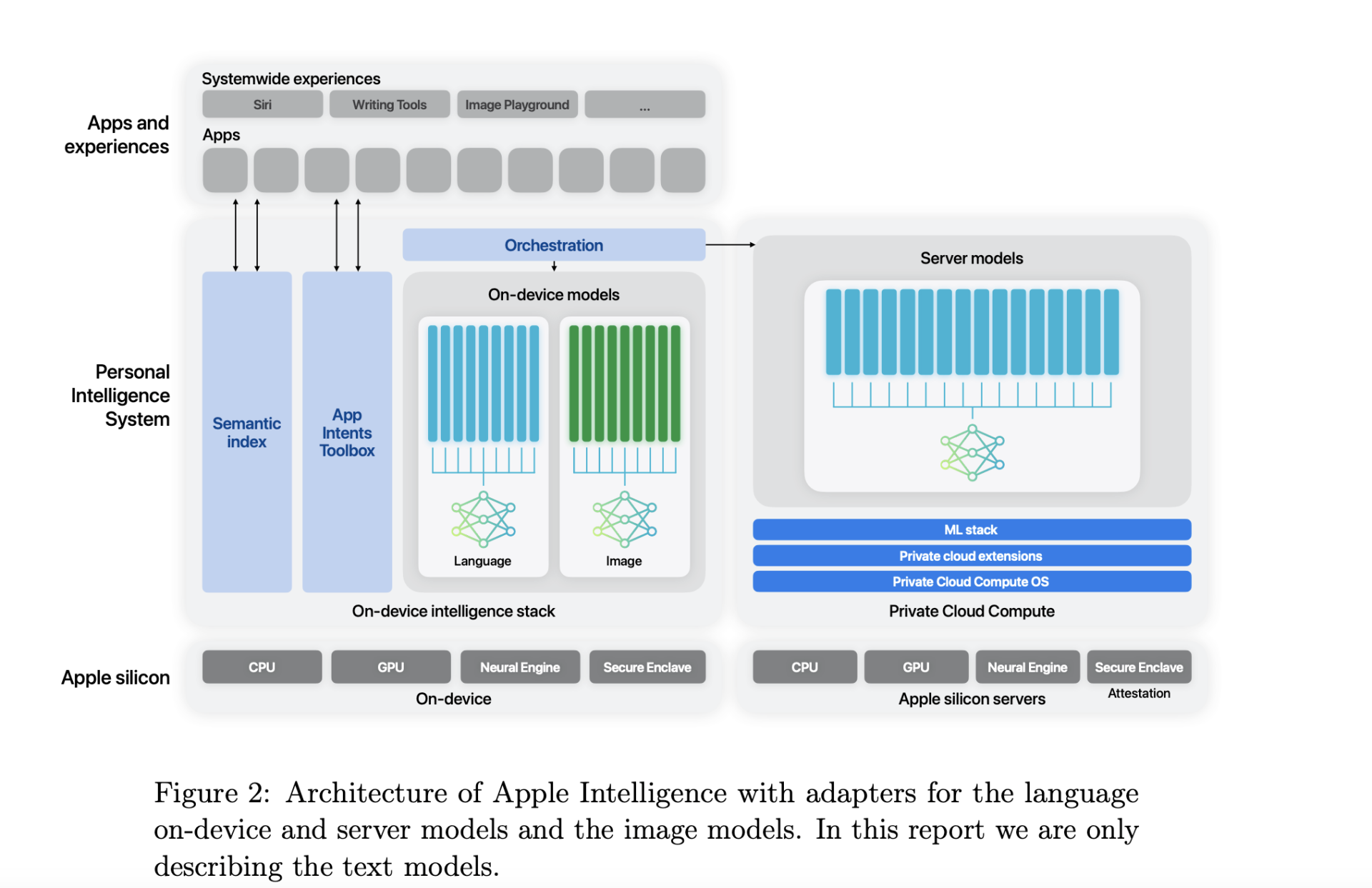
Zu den weiteren Details in der Arbeit gehört die Bewertung des Modells hinsichtlich schädlicher Reaktionen, sensibler Probleme, sachlicher Korrektheit, mathematischer Leistung und menschlicher Zufriedenheit mit der Ausgabe des Modells. Laut Apple sind AFM-Server- und On-Device-Modelle branchenweit führend bei der Unterdrückung bösartiger Ausgaben.
Beispielsweise hatte der AFM-Server eine Rate böswilliger Ausgabeverstöße von 6,3 %, verglichen mit GPT-4 von OpenAI, der eine Rate von 28,8 % aufwies. Ebenso wies das AFM auf dem Gerät eine Verletzungsrate von 7,5 % auf, verglichen mit dem Wert von Llama-3-8B von 21,8 %.
Bei der Zusammenfassung von E-Mails, Nachrichten und Benachrichtigungen erreichte das On-Device AFM eine Zufriedenheitsrate von 71,3 %, 63 % bzw. 74,9 %. Das Forschungspapier teilte mit, dass diese den Llama-, Gemma- und Phi-3-Modellen voraus waren.


