20 Mär
grafikkarte

Nvidia hat seinen neuesten KI-Chip namens Blackwell vorgestellt, der bei bestimmten Aufgaben 30-mal schneller ist als sein Vorgänger. Das Unternehmen, das einen Marktanteil von 80 % hat, hofft, seine Dominanz auf dem Markt zu festigen. Zusätzlich zum B200 „Blackwell“-Chip stellte Firmenchef Jensen Huang auf der jährlichen Entwicklerkonferenz des Unternehmens eine Reihe neuer Softwaretools vor.
Benannt nach Dr. David Harold Blackwell, ein amerikanischer Pionier in Statistik und Mathematik, der unter anderem das erste Bayes'sche Statistiklehrbuch geschrieben hat, setzt die Blackwell-Architektur erneut darauf, dass NVIDIA bei vielen KI-Designs des Unternehmens stark darauf setzt. NVIDIA hat mit dem Hopper (und Ampere davor) etwas wirklich Gutes vorzuweisen, und insgesamt möchte Blackwell mehr davon anbieten, aber mit mehr Funktionen, mehr Flexibilität und mehr Transistoren.

Als Erstes ist zu beachten, dass die Blackwell-GPU groß sein wird. Buchstäblich. Die B200-Module, in die es eingebaut wird, werden über zwei GPU-Chips auf einem einzigen Gehäuse verfügen. NVIDIA ist bei seinen Flaggschiff-GPUs endlich auf Chiplet-Designs umgestiegen. Sie verraten zwar nicht die Größe der einzelnen Matrizen, uns wurde jedoch mitgeteilt, dass es sich um Matrizen in „Retikelgröße“ handelt, was einer Größe von etwa über 800 mm² pro Matrize entspricht. Der GH100-Chip lag bereits nahe an den 4-nm-Retikelgrenzen von TSMC, daher gibt es für NVIDIA hier nur sehr wenig Spielraum für Wachstum – zumindest ohne innerhalb eines einzelnen Chips zu bleiben.
Kurioserweise verwendet NVIDIA trotz dieser Einschränkungen beim Chip-Platz keinen TSMC-Knoten der 3-nm-Klasse für den Blackwell. Technisch gesehen verwenden sie einen neuen Knoten – den TSMC 4NP – aber dies ist nur eine Hochleistungsversion des 4N-Knotens, der für die GH100-GPU verwendet wurde. Das bedeutet, dass praktisch alle Effizienzgewinne von Blackwell aus architektonischer Effizienz resultieren müssen, während eine Mischung aus dieser Effizienz und dem Umfang der Skalierung die Gesamtleistungsverbesserungen von Blackwell bewirken wird.
Obwohl NVIDIA an einem Knoten der 4-nm-Klasse festhält, ist es ihm gelungen, mehr Transistoren auf einem einzigen Chip unterzubringen. Die Transistorzahl für den gesamten Beschleuniger beträgt 208 Milliarden bzw. 104 Milliarden Transistoren pro Stück sterben. Der GH100 bestand aus 80 Milliarden Transistoren, sodass jeder B100-Chip insgesamt etwa 30 % mehr Transistoren hat, ein bescheidener Gewinn im Vergleich zu historischen Standards. Aus diesem Grund sehen wir, dass NVIDIA mehr Chips in seine gesamte GPU einbaut.
Bei seinem ersten Multi-Die-Chip ist NVIDIA entschlossen, die umständliche Phase „zwei Beschleuniger auf einem Chip“ zu überspringen und direkt dazu überzugehen, dass sich der gesamte Beschleuniger wie ein einziger Chip verhält. Laut NVIDIA fungieren die beiden Chips als „einheitliche CUDA-GPU“ und bieten volle Leistung ohne Kompromisse. Der Schlüssel dazu ist die I/O-Verbindung mit hoher Bandbreite zwischen den Chips, die NVIDIA als NV-High Bandwidth Interface (NV-HBI) bezeichnet und eine Bandbreite von 10 TB/Sekunde bietet. Vermutlich liegt es in aggregierter Form vor, was bedeutet, dass die Chips gleichzeitig 5 TB/Sekunde in jede Richtung senden können.

Beim B200 ist jeder Chip mit 4 Stapeln HBM3E-Speicher gepaart, also insgesamt 8 Stapel, was eine effektive Speicherbusbreite von 8192 Bit ergibt. Einer der limitierenden Faktoren bei allen KI-Beschleunigern war die Speicherkapazität (nicht zu unterschätzen ist auch der Bedarf an Bandbreite). Daher ist die Möglichkeit, mehr Stapel einzubeziehen, für die Verbesserung der lokalen Speicherkapazität des Beschleunigers enorm wichtig. Insgesamt bietet das B200 192 GB HBM3E, also 24 GB pro Stapel, der mit der Kapazität von 24 GB pro identisch ist Stack für den H200 (und 50 % mehr Speicher als die ursprünglichen 16 GB pro Stack H100).
Laut NVIDIA verfügt der Chip über eine gesamte HBM-Speicherbandbreite von 8 TB/Sekunde, was 1 TB/Sekunde pro Sekunde entspricht Stack – oder eine Datenrate von 8 Gbit/s/Pin. Wie wir in unserer vorherigen Berichterstattung über den HBM3E festgestellt haben, ist der Speicher letztendlich darauf ausgelegt, 9,2 Gbit/s/Pin oder mehr zu erreichen, wir stellen jedoch oft fest, dass NVIDIA mit den Taktraten seiner Serverbeschleuniger etwas konservativ umgeht. In jedem Fall ist dies fast 2,4-mal so viel Speicherbandbreite wie beim H100 (oder 66 % mehr als beim H200), sodass NVIDIA eine deutliche Steigerung der Bandbreite verzeichnet.
Schließlich liegen uns derzeit keine Informationen zur TDP eines einzelnen B200-Beschleunigers vor. Zweifellos wird es hoch sein – Sie können Ihre Transistoren in einem nicht mehr als verdoppeln und eine Art Einbuße hinsichtlich des Stromverbrauchs vermeiden. NVIDIA wird sowohl luftgekühlte DGX-Systeme als auch flüssigkeitsgekühlte NVL72-Racks verkaufen, sodass der B200 nicht außerhalb der Reichweite der Luftkühlung liegt.

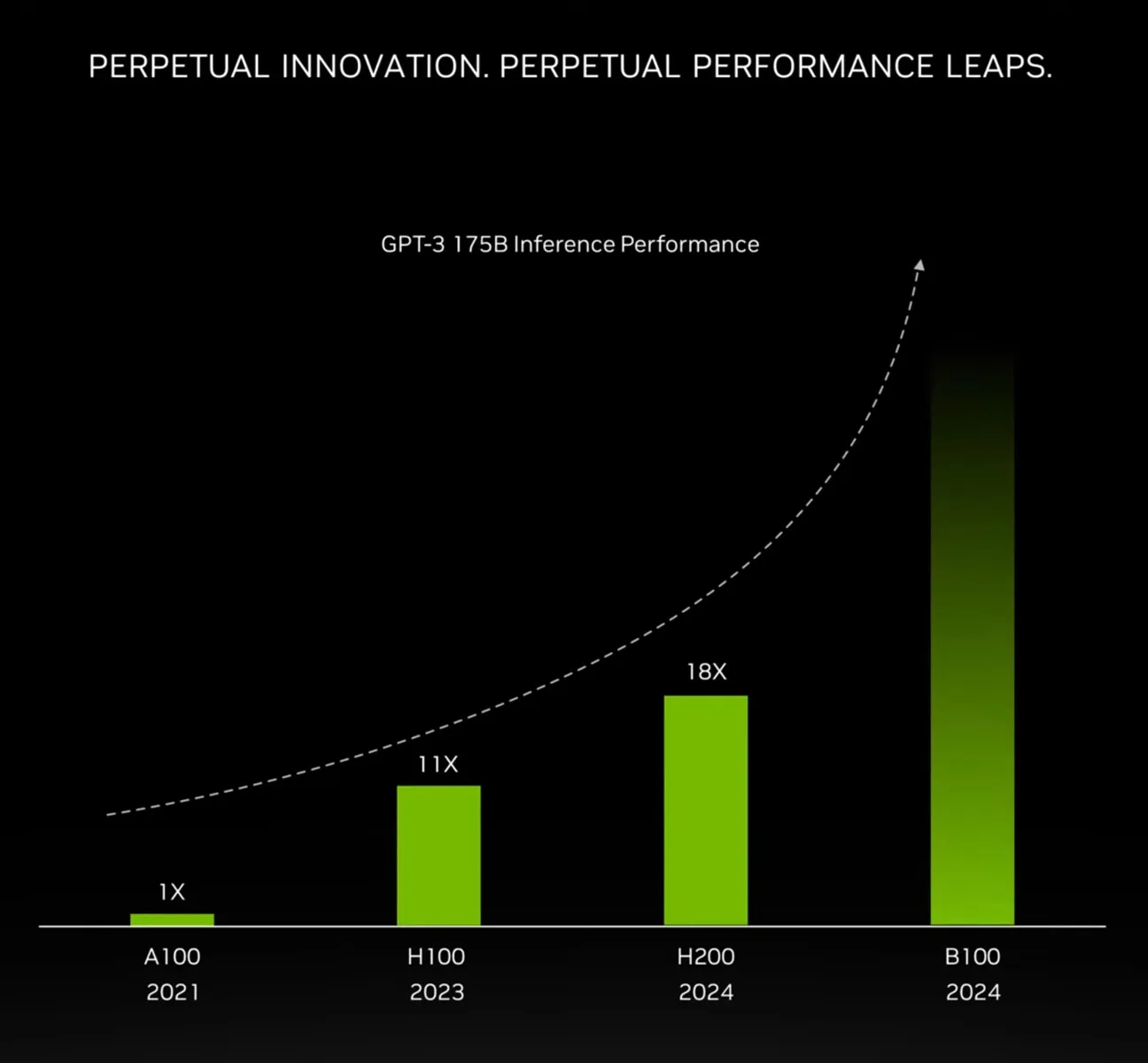
Insgesamt strebt NVIDIA eine 4-fache Steigerung der Trainingsleistung gegenüber dem H100 auf Clusterebene und eine noch größere 30-fache Steigerung der Inferenzleistung an, und das bei einer 25-fach höheren Energieeffizienz.
Nvidia ist das drittwertvollste Unternehmen in den USA, nur übertroffen von Microsoft und Apple. Seine Aktien sind im vergangenen Jahr um 240 % gestiegen und seine Marktkapitalisierung erreichte letzten Monat 2 Billionen US-Dollar.
Als Herr Huang die Konferenz eröffnete, sagte er scherzhaft: „Ich hoffe, Ihnen ist klar, dass dies kein Konzert ist.“ Nvidia sagte, dass Großkunden wie Amazon, Google, Microsoft und OpenAI den neuen Flaggschiff-Chip des Unternehmens voraussichtlich in Cloud-Computing-Diensten und für ihre eigenen KI-Angebote nutzen werden. Außerdem hieß es, dass die neuen Softwaretools, sogenannte Microservices, die Systemeffizienz verbessern und es einem Unternehmen einfacher machen, ein KI-Modell in seine Arbeit zu integrieren.
Zu den weiteren Ankündigungen gehört eine neue Reihe von Chips für Autos, die Chatbots im Fahrzeug ausführen können. Das Unternehmen sagte, die chinesischen Elektroautohersteller BYD und Xpeng würden beide seine neuen Chips verwenden. Herr. Huang stellte außerdem eine neue Serie von Chips zur Herstellung humanoider Roboter vor und lud mehrere der Roboter mit auf die Bühne.


